
MINI-DAIL: A simple yet efficient way to turn Natural Language questions into SQL

INTRODUCTION
Text-to-SQL is a task in natural language processing (NLP) that aims to automatically generate SQL query from natural language text, to bridge the gap between non-expert users and database systems. It greatly improved the efficiency of data processing and contributed to a wider range of applications such as intelligent database service, automatic data analysis and database question-answering.
However, at its core, it presents multitude of challenges, the difficulty arises mainly from the vast differences between human language, which is fluid and context-dependent, and SQL, which is a precise and structured language.
With the emergence of LLMs and different prompting techniques, the Text-to-SQL landscape has undergone a significant transformation. Demonstrating exceptional performance, LLMs are able to generate precise SQL from natural language content, an achievement made possible by their vast knowledge base and contextual awareness capabilities.

One highly effective and efficient approach in optimizing the utilization of LLMs for Text-to-SQL is DAIL-SQL. This method has demonstrated its superiority by achieving an impressive score of 86.2% on the Spider leaderboard using GPT-4 during testing.
In simple words, DAIL-SQL is a sophisticated prompt engineering method, that focuses on optimizing three fundamental prompting techniques which are:
Example selection
Example organization
Question representation
LET’S TALK A BIT ABOUT SPIDER DATASET
The Spider Dataset is a widely recognized and esteemed dataset in the field of text-to-SQL, it holds significant prominence as it serves as a benchmark for evaluating the performance of various Language Models (LLMs) and emerging techniques within the text-to-SQL domain.
It is considered one of the largest and most diverse datasets in this area as it consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases[1] with multiple tables covering 138 different domains.
The Spider data is split into the following sets:
Train_spider set: contains 7000 examples.
train_others set: contains 1695 example.
dev set: contains 1034 examples.
Each of these sets has a separate SQL Text File that contains the ground truth queries (or gold queries).
DAIL-SQL :
Before diving deep into our proposed solution, let’s explain the techniques of our inspiration ,DAIL-SQL, starting with the first one which is:
Example Selection :
This method is designed to identify a specific number of closely related candidates from a given dataset. It begins by masking domain-specific terms in both the user's input question and a set of example questions, using matching based schema linking mechanism, It then ranks the candidate examples based on the Euclidean distance between the embeddings of the masked questions . Simultaneously, it calculates the query similarity between the pre-predicted SQL query and the present queries in the dataset. Finally, the selection criterion prioritizes the sorted candidates by question similarity with a query similarity greater than a predefined threshold. In this way, the selected top 𝑘 examples have good similarity with both question and query.
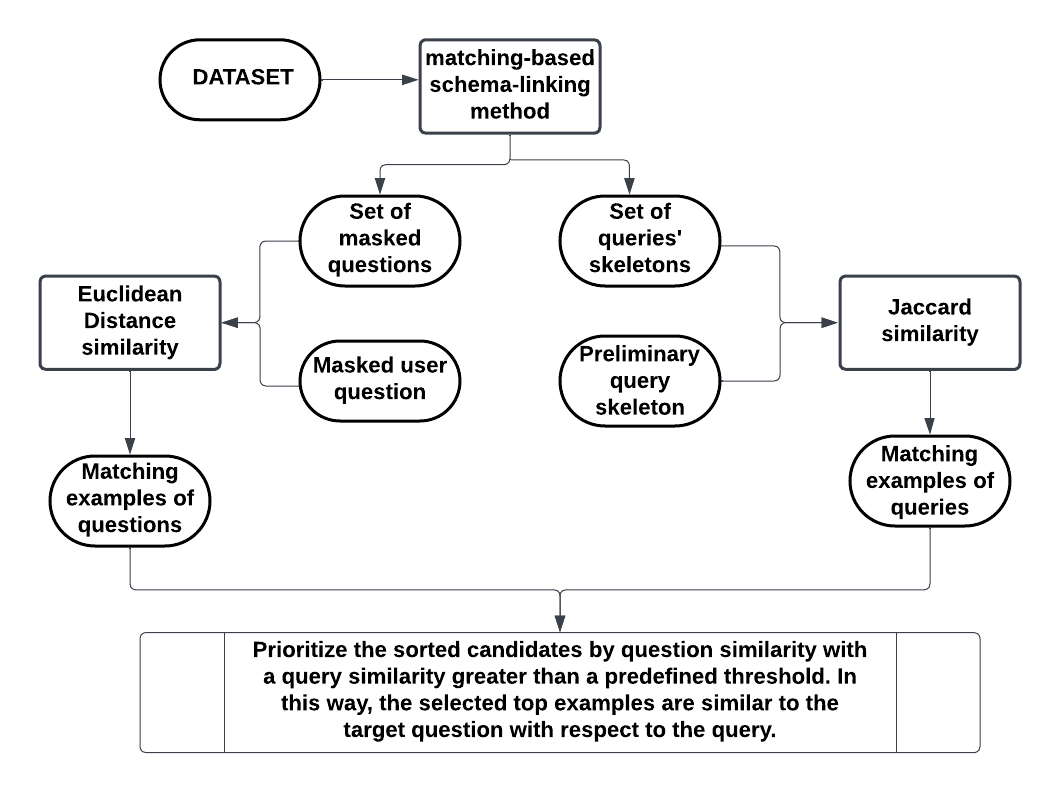
Example Organization :
To preserve the mapping information between questions and SQL queries and also improve the token efficiency, DAIL-SQL presents both the questions and queries, as illustrated in the figure below:

Question Representation :
DAIL-SQL adopts Question Representation, because it contains full database information, including primary and foreign keys. This provides useful information for Language Model Models (LLMs), aiding in the prediction of "JOIN" clauses, and ensuring a right adequate query generation.

OUR SOLUTION: MINI-DAIL
We introduce MINI-DAIL, a simplified, easy to test and integrate solution, based on DAIL-SQL.
The primary differentiator between our solution and DAIL-SQL, lies in the example selection prompting. Instead of masking the questions, we have incorporated two selectors : Cosine similarity and Euclidean Distance similarity, who relies on the embeddings of the user question and the questions within the Spider train set, to retrieve the top k resembling examples.
What steps does MINI-DAIL follow ?
Our solution takes both the user question and the corresponding database schema as input, proceeding through the following steps:
Example Selection (1st Step):
Read the Spider dataset.
Extract embeddings from the train set (we combined both train_spider and train_others to create this set).
Define the number of examples to extract.
Retrieve examples based on the chosen selector.
Example Organization (2nd Step):
Map the corresponding query for each selected example.
Code Representation (3rd Step):
Format the data into the DAIL-SQL prompt, incorporating examples, queries, and the database schema.
Pass the formatted DAIL-SQL prompt to the selected LLM, allowing it to generate the desired query.

Results:
To test our solution’s performance, We used test suite accuracy metric, this metric gives insights on two aspects. Firstly, execution accuracy, evaluates the generated query by determining whether its execution on the dataset gives a correct output. Secondly, exact match accuracy which evaluates the structural alignment between the generated query and the ground truth query.
We evaluated MINI-DAIL with GPT 3.5 turbo as our LLM, on Spider dev set, which contains 1034 examples:

Overall, MINI-DAIL demonstrates a promising execution accuracy of approximately 71.0% when executing SQL queries on databases. However, its exact matching accuracy, averaging at 56.1%, reveals a notable decrease as queries grow in complexity. This suggests that while the model executes SQL queries on databases and extracts the desired outputs in most cases, its ability in precisely predicting the structure of queries diminishes, especially with more complex queries.
Is MINI-DAIL fast ?
To gain deeper insights into the efficiency of our solution, we calculated the time taken by MINI-DAIL to traverse through all the prompt steps and generate the desired template we need to send to the LLM.
As the above figure shows, the majority of examples fall within the range of 0.05 to 0.2 seconds, indicating that most instances are processed relatively quickly. However, it's worth noting that there are some examples where the process lasts a bit longer ( approximatively from 0.35 to 0.55 seconds).
Overall, the visualization suggests that MINI-DAIL generally performs efficiently in generating the prompt template, with the majority of cases being processed within a reasonable timeframe.

As for the response time (time taken to prepare the prompt from MINI-DAIL and query the LLM, GPT 3.5 Turbo, to extract the response), on average, each request has a response time of 2 seconds, with the majority of requests being processed within the range of 1 to 4 seconds.
The maximum and minimum response times recorded were 9.635 seconds and 1.0 seconds, respectively.

Is MINI-DAIL expensive ?
To estimate the cost spent on processing 1034 examples using OpenAI models, we generated 2 histograms comparing the pricing of both GPT-4 and GPT-3.5 Turbo on the examples we worked with:

In the case of GPT-3.5 Turbo, the majority of examples are concentrated within the lower cost range of $0.001 to $0.0025 per example

Conversely, GPT-4 exhibits a shift towards higher costs, with most examples falling within the range of $0.01 to $0.025 per example (10 times more expensive).
While GPT-4 holds promise for generating better responses, integrating it into a solution for our users is a costly decision. GPT-3.5 offers a cost-effective alternative, being approximately ten times cheaper than its successor, that is why harnessing its potential and fine-tuning its performance to better align with our case, is what we opt to do in our future steps.
Future Work:
Add Schema Linking and masking process :
To further improve our results, we can enhance the Example Selection method by incorporating the masking process approach. This step is essential for improving the quality of selected questions and ensuring they closely resemble the target question.
Add fine tuning steps :
Pre-trained models like GPT-3.5 have been trained on massive datasets to learn general linguistic skills and knowledge. This gives them strong capabilities out of the box.
However, their knowledge is still general. To adapt them to specialized domains and tasks, we can create fine-tuning jobs to adjust their internal weights to bias it towards the Spider data.
Bibliography:
 | A guest post by
|