
DAIL-SQL: Enhanced SQL Query Generation with LLMs and advanced RAG




LLMs are revolutionizing the Text-to-SQL landscape
Text-to-SQL (Structured Query Language) is a challenging natural language processing task that aims to bridge the gap between queries in human language and precise SQL queries. Benchmark datasets such as Spider provide a standardized platform for evaluating Text-to-SQL models and techniques by offering a diverse range of real-world SQL queries paired with natural language questions.
The recent advancements in Large Language Models (LLMs) particularly with techniques like prompt engineering and RAG (Retrieval-Augmented Generation), have revolutionized the field of natural language understanding and generation. These techniques leverage large pre-trained language models to generate more accurate and contextually relevant responses.
In the context of the Text-to-SQL task, DAIL-SQL has emerged as a state-of-the-art approach, consistently ranking high on the Spider leaderboard. DAIL-SQL demonstrates impressive performance in accurately converting natural language questions into SQL queries, showcasing the effectiveness of advanced techniques like prompt engineering and fine-tuning on Text-to-SQL task.
Building upon the success of DAIL-SQL and drawing inspiration from advancements in prompt engineering and example selection techniques, we introduce our adaptation, a solution tailored to capitalize on DAIL-SQL's strengths in SQL query generation, and to seamlessly accommodate any user query by leveraging schema linking, masking, and refined example selection methods to optimize accuracy and relevance.
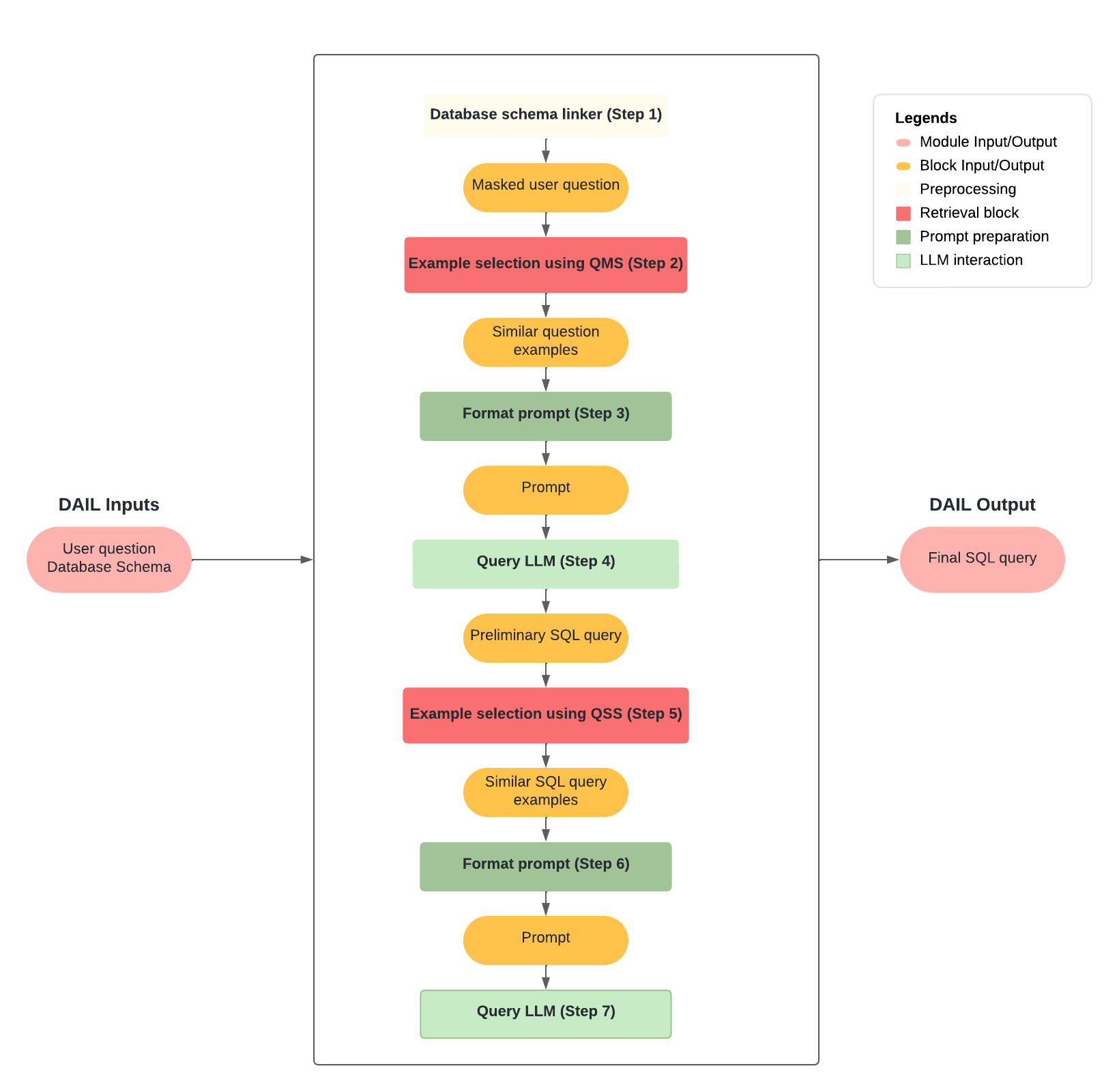
General architecture of DAIL-SQL algorithm:
Our implementation, inspired by DAIL-SQL, works by leveraging database schema information and strategically masking tokens in user queries to enhance example selection and allow for cross-domain examples that closely align with the user query, further boosting the accuracy of generated SQL queries. It operates by following these steps:
Question Masking:
Using the database schema and the user's question, the Database Schema Linker (DSL) identifies specific tokens in the question that should be masked. These tokens typically represent entities within the database, such as column or table names, or values present in the database.
Question based example selection:
The Question Masking Selector (QMS) retrieves examples from the Spider training split that are most similar to the masked question. These examples serve as reference points for generating SQL queries that are relevant to the user's query.
Prompt formatting:
The retrieved examples are formatted into a DAIL-SQL prompt, which includes examples, queries, and the database schema. This formatted prompt provides the necessary context for the Language Model (LLM) to generate SQL queries.
First LLM interaction:
The prompt is passed to the selected LLM, enabling it to generate a preliminary SQL query based on the provided examples and schema information.
Query based example selection:
Using the preliminary SQL query generated by the LLM, the Query Skeleton Selector (QSS) retrieves additional examples from the Spider training split that are most similar to the generated query. These examples provide further context for refining the SQL query.
Prompt formatting:
The examples selected from QSS will be merged with the examples selected from QMS to enrich the prompt.
Second LLM interaction:
Using the merged examples from QMS and QSS, a final DAIL-SQL prompt containing all examples, is then passed to the selected LLM to generate the final SQL query.
Deep dive on core components of DAIL-SQL algorithm:
Database Schema Linker:
DSL serves as a pivotal component in our implementation, facilitating the process of question masking. Its primary function is to identify specific tokens within the user's question that require masking. such tokens stand for elements found within the database, like names of columns or tables, or the data values stored in the database.
By identifying and masking these tokens, DSL enhances the system's understanding of the user's query and ensures that the generated SQL queries are contextually relevant and accurate. Additionally, it enables cross-domain example retrieval, allowing the system to fetch examples not necessarily related to the user's database domain.
For instance, if a user queries a database storing banking information, the retrieved examples may come from finance or travel databases, as long as the context of the question remains the same, ensuring that the questions have similar structures.
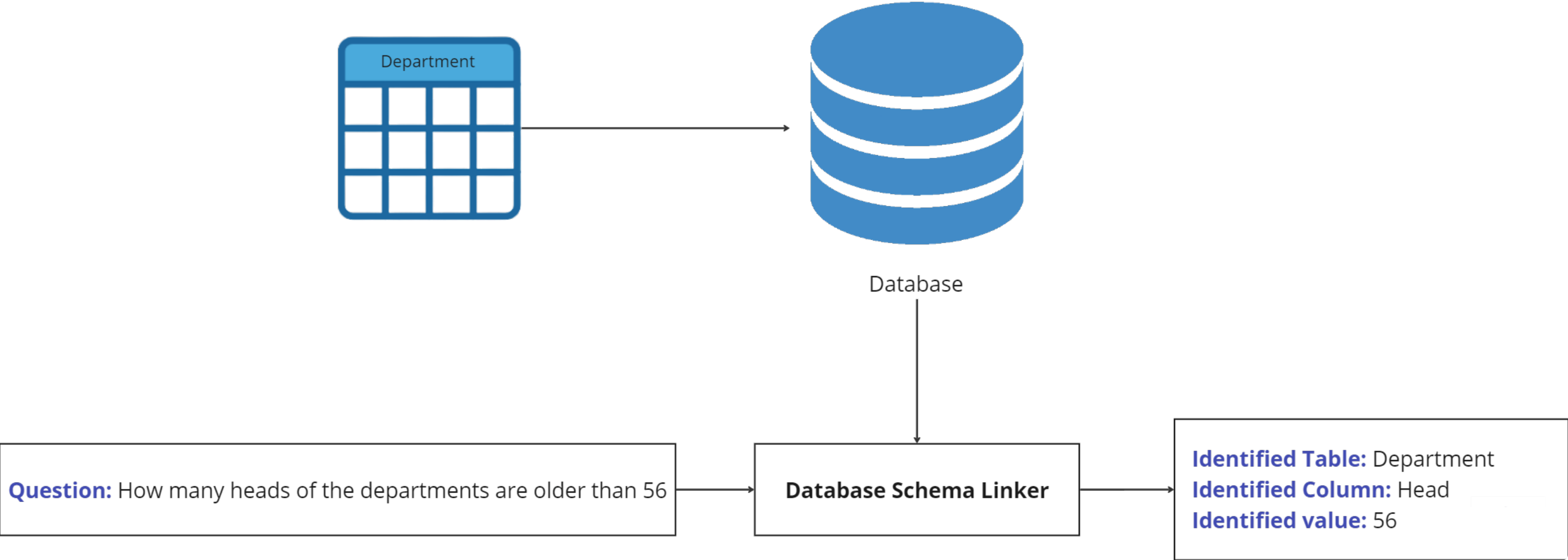
In essence, DSL serves as a connection between the user's query expressed in natural language and the structured data stored within the database.
Advanced Example selection:
Selection based on masked question (QMS):
The first selector will leverage the power of DSL and RAG to retrieve the best examples from Spider train split stored in a Vector Database, based on its results, QMS will mask the tokens and then conduct example selection using Euclidean distance.

Selection based on SQL query skeleton (QSS):
The second selector operates by comparing the SQL query skeleton of a target with the query skeletons of examples stored in the Vector Database. QSS identifies the most relevant examples based on Jaccard similarity between the target's query skeleton and each stored example's query skeleton.

Experimental results of our implementation vs DAIL-SQL paper:
We evaluated our implementation by employing SQL Eval test suite, which offers insights into two key aspects.
Firstly, it assesses execution accuracy by verifying if the query generated by our solution yields correct results when executed on the dataset.
Secondly, it measures exact match accuracy, which evaluates the structural alignment between the generated query and the ground truth query.
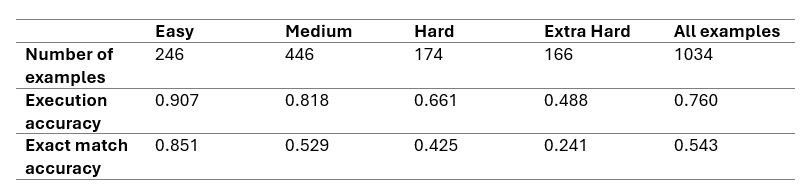
Our evaluation was conducted using GPT 3.5 Turbo as our language model, on the Spider development set, which comprises 1034 examples, the following are the highest obtained results:
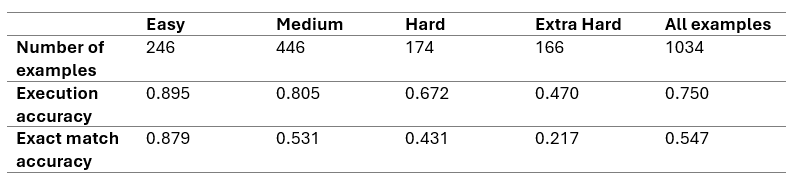
Compared to the previous results, we managed to leverage an increase of 4% in execution accuracy (from 71% to 75%), thanks to the new components bringing us closer to the results attained by DAIL-SQL.
However, we made some intriguing discovery. We conducted a comparison between using a single selector (QMS) and both selectors (QMS + QSS). Surprisingly, we observed a slight increase in execution accuracy in favor of exact match accuracy using QMS only, highlighting a trade-off between the complexity of prompt techniques and the performance of LLMs.
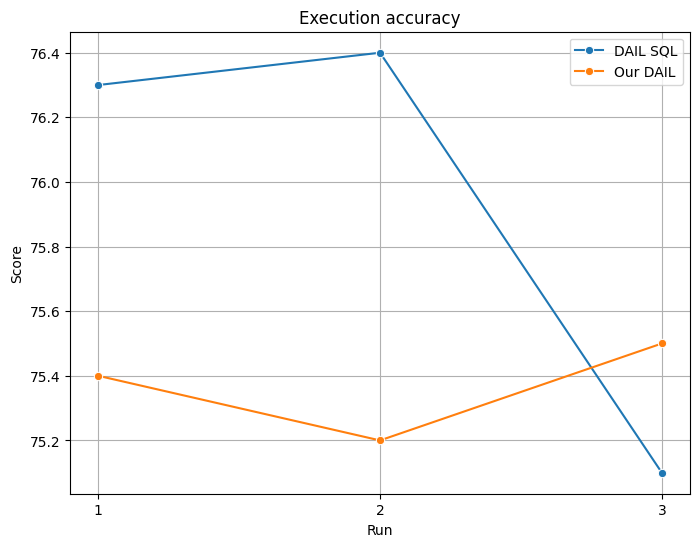
It's important to highlight that ensuring reproducibility of the LLM wasn't feasible. Therefore, to ensure a comprehensive perspective, we conducted multiple iterations comparing DAIL-SQL and our implementation to validate our findings.
Below are the results from our evaluation on Execution accuracy, which assesses the correctness of generated SQL queries when executed on the dataset:
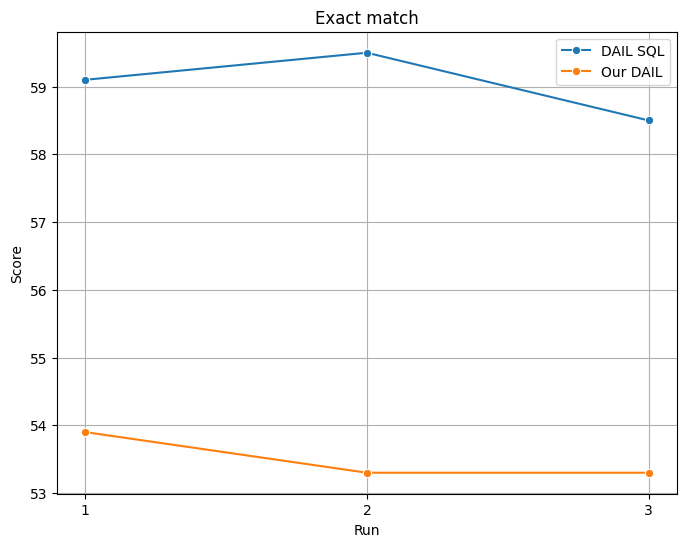
And our evaluation on Exact match, which examines how closely the generated SQL query matches the ground truth query in structure:
Is DAIL-SQL time efficient?
To check the efficiency of our solution, we measured the time taken to traverse all prompt steps and generate the required prompt for LLM interactions.
The distribution of elapsed time required to construct prompts and query the Large Language Model (LLM) twice shows that the majority of examples typically fall within the range of 1.5 to 4 seconds. This suggests that the processing of most instances occurs within a reasonable amount of time.
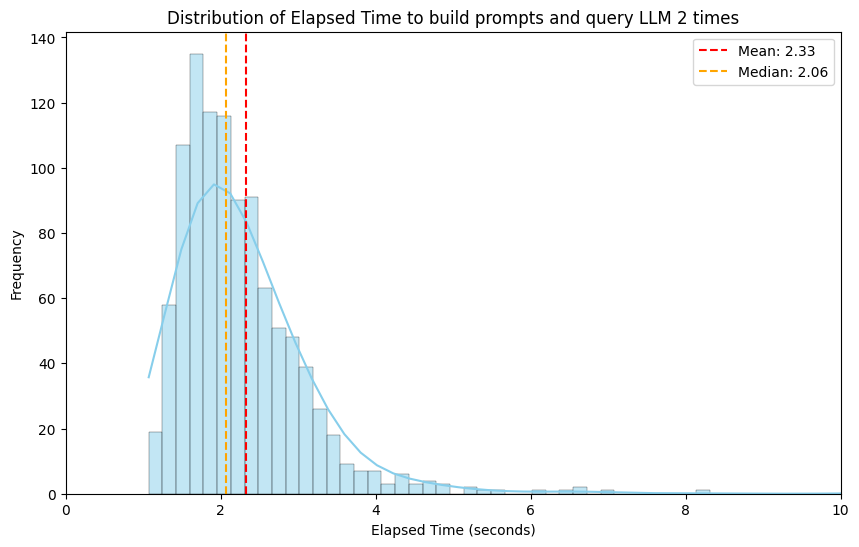
Overall, our implementation demonstrates efficient prompt template generation, with the majority processed within a reasonable timeframe.
Is DAIL-SQL cost efficient?
To estimate the expenses associated with evaluating our solution using Open AI models, we generated two histograms to compare the pricing between GPT-4 and GPT-3.5 Turbo.
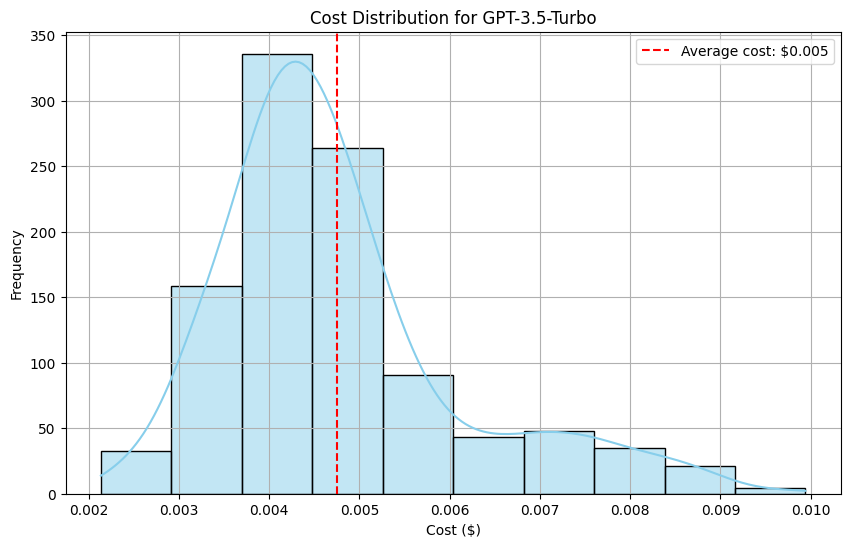
For GPT-3.5 Turbo, most examples fall within the lower cost bracket, ranging from $0.003 to $0.006 per example.
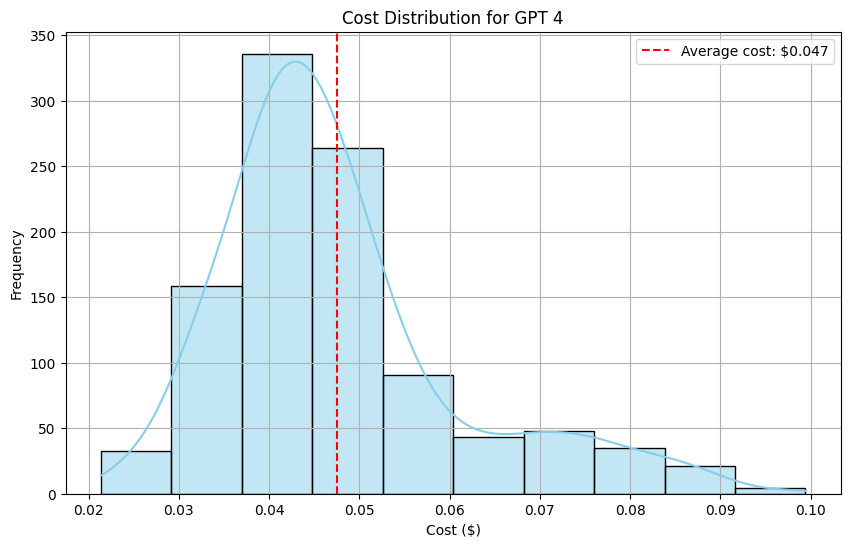
On the other hand, GPT-4 demonstrates a shift towards elevated costs, with the majority of examples ranging from $0.03 to $0.06 per example (ten times more expensive).
Conclusion and way forward
The implementation presented in this article marks a significant step forward in revolutionizing text-to-SQL queries. With its advanced RAG capabilities, efficient database schema linking, and precise example selection, it promises improved efficiency and cost-effectiveness.
Moving forward, our next steps will involve deploying this solution in real-world scenarios and exploring fine-tuning approaches using Large Language Models (LLMs).
By continuing to innovate and refine our methods, we aim to further optimize text-to-SQL processes and unlock even greater potential in data query generation.
Bibliography:
 | A guest post by
|